Ask a typical RAG system this: "What did I discuss last Monday about authentication?"
The semantic channel happily matches "authentication" against a dozen memories. The phrase "last Monday" is thrown away silently — because cosine similarity on a single embedding vector has no concept of time. The system returns the most semantically similar result, which may be from three months ago, and moves on.
This isn't a model quality problem. It's a retrieval architecture problem. Single-vector cosine similarity is a great building block for one kind of matching — conceptual similarity. But agent memory has to handle queries that hinge on time, exact identifiers, entity relationships, and emotional context. None of those signals survive a trip through a single embedding space.
MetaMemory's retrieval layer uses five channels. Each targets a different kind of signal. They run in parallel, produce independent ranked lists, and fuse through weighted Reciprocal Rank Fusion. This post explains why.
Assumed audience: You've built something with RAG, you know what cosine similarity does, and you've been bitten at least once by a retrieval result that was semantically close but contextually wrong.
The Query Types That Break Single-Vector Retrieval
Before explaining the architecture, it's worth being concrete about where single-vector retrieval silently fails. These aren't edge cases — they're the bulk of real agent queries.
Temporal anchors. "What happened last Tuesday?" "Show me the last thing we discussed about X." The temporal anchor is a hard filter in the user's head, but to cosine similarity it's just a few more tokens to average into the query vector. If the highest-similarity match is from last month, that's what gets returned.
Multi-hop reasoning. "Who was the person my manager mentioned in the architecture review?" The answer requires chaining: manager → architecture review → person mentioned. Dense retrieval flattens this into a single vector and hopes a memory happens to sit nearby in the embedding space. Usually one doesn't.
Exact-match identifiers. "Find the memory where error code E_AUTH_404 came up." Dense embeddings are robust to paraphrasing, which is usually what you want — but it's catastrophic when you need the exact token. The embedding treats E_AUTH_404 as semantically similar to "authentication failure", which buries the one memory that actually mentions the code.
Emotional context. "When was the user frustrated with onboarding?" The word "frustrated" might not appear anywhere in the memory. Frustration was inferred from behavioral signals — retry counts, error patterns, session duration. A semantic embedding of the word "frustrated" has no way to find those memories.
Each of these is a missing retrieval signal. You can't fix them by improving the embedding model. You fix them by adding channels.
The Five Channels
MetaMemory's retrieval layer exposes five channels. Each handles one kind of signal, uses the data store best suited to it, and produces its own ranked list.
1. Semantic. Dense vector cosine similarity over the memory's semantic embedding. Stored in pgvector. This is the workhorse — it handles the "what was discussed" dimension and catches conceptually related memories even when the wording differs. It's also the channel most other systems stop at.
2. Temporal. Combines semantic similarity with an exponential recency decay term. The scoring blends content match and time-weighted relevance, so "what did we discuss last week" actually surfaces last week's conversations instead of the most conceptually similar one from last year. Supports both exponential and power-law (FSRS-style) decay for different memory lifespans.
3. Emotional. Similarity over emotional trajectory embeddings — the 132-dimensional vectors that encode the shape of an emotional arc, not just a point-in-time state. Falls back to tag-based matching with an intensity threshold when no trajectory is available. This is the channel that answers "find memories where the user had a similar emotional experience" without matching on the word itself.
4. Keyword. BM25-style full-text search via PostgreSQL's ts_rank_cd. This is the channel that rescues exact identifiers, error codes, names, and technical terms. Dense retrieval will happily paraphrase these away; keyword retrieval refuses to. The two are complementary, not competing — you want both.
5. Graph. Spreading activation over a Neo4j knowledge graph. Seeds from entity extraction or the top-K semantic results, then propagates activation along typed edges (SHARES_ENTITY, SIMILAR_TO, IN_SAME_EPISODE, etc.) with a decay factor per hop. This is the channel that handles multi-hop queries — the kind where the answer is connected to the query through two or three relationship edges rather than vector proximity.
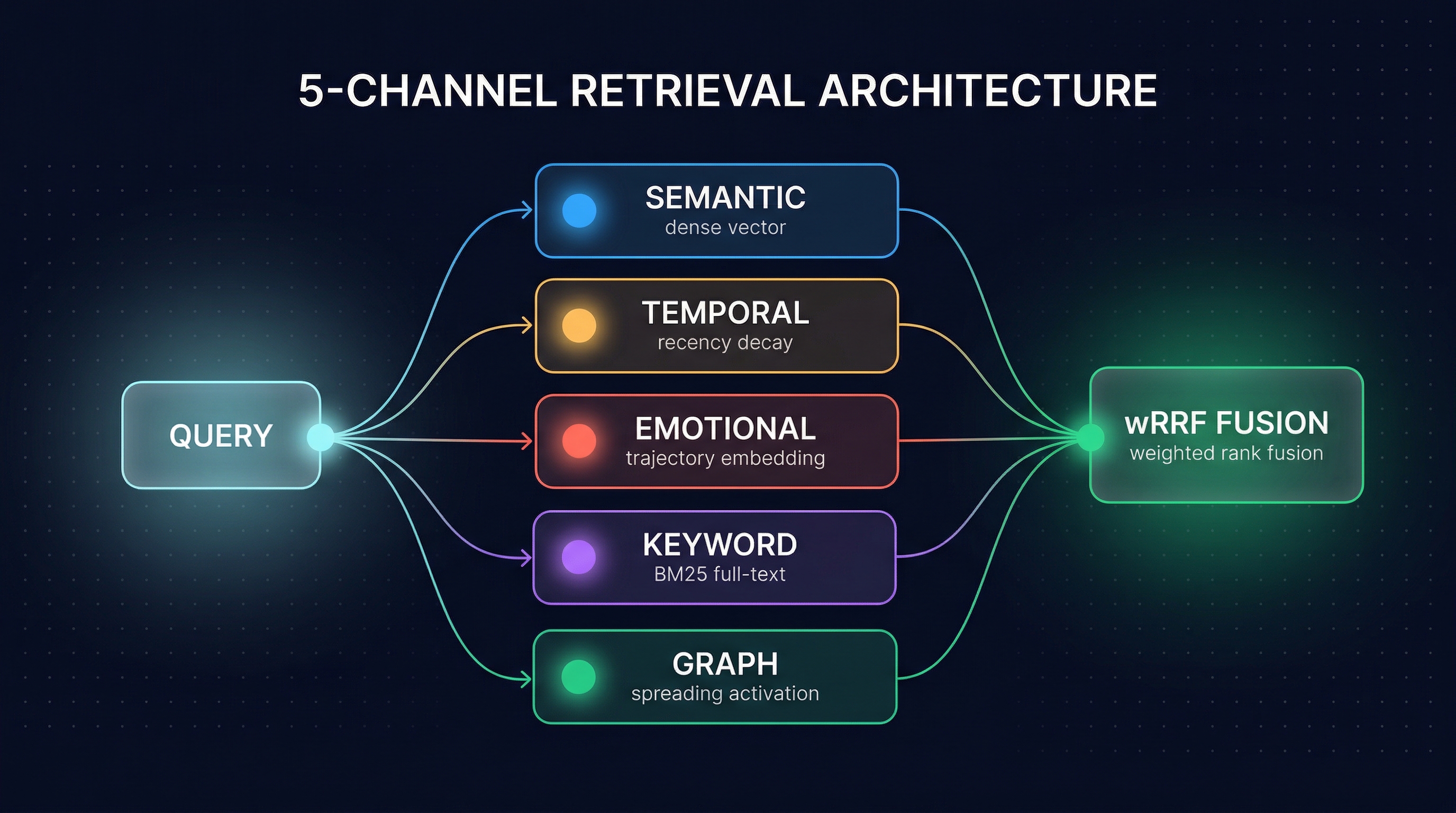
How the Channels Fuse: Weighted Reciprocal Rank Fusion
Each channel runs in parallel, independently, and produces its own ranked list of candidate memories. The lists are then fused into a single ranking using weighted Reciprocal Rank Fusion (wRRF), based on Cormack et al. 2009:
wRRF(d) = Σ_c [ w_c / (k + rank_c(d)) ]
Where w_c is the weight of channel c, rank_c(d) is the 1-based rank of document d in that channel's list, and k is a smoothing constant (default 60, per the original paper).
Two things make RRF the right choice over naive score averaging:
No score normalization needed. A semantic channel returns cosine similarities in [0, 1]. A keyword channel returns BM25 scores that are unbounded and not directly comparable. A graph channel returns activation values in yet another scale. Trying to normalize these into a single averaged score introduces calibration problems that never fully go away. RRF sidesteps all of it — it only cares about rank order.
Multi-channel documents are reinforced naturally. A memory that appears at rank 1 in both the semantic and keyword channels gets w_sem/61 + w_kw/61, which puts it decisively above a memory that appears at rank 1 in only one channel. The system rewards documents that multiple signals agree on, without any explicit consensus logic.
Query-Type Routing: Not Every Channel Gets Equal Weight
Default weights work well for general queries. But a temporal query shouldn't weight the semantic channel the same as a factual query does. MetaMemory detects the query type and adjusts per-channel weights accordingly.
The weight matrix lives in the retrieval config — five query types, five channels per type. For each query type, one channel is the dominant voice in the fusion and the rest play supporting roles. Temporal queries boost the temporal channel. Factual queries boost keyword. Multi-hop queries boost graph. And so on.

Notice what doesn't happen: no channel gets disabled for any query type. All five still run in parallel. The routing only shifts which channel's votes count more in the final fusion. This matters because real queries are rarely cleanly typed — a "temporal emotional" query ("when was the user frustrated last week?") benefits from multiple channels still contributing.
The matrix above shows the starting point, not a fixed configuration. MetaMemory's meta-learning layer observes which channels actually produced the results users engaged with, and adapts the weights per context over time. Two deployments running the same architecture will end up with different weight matrices because they serve different query distributions. What you see at launch is a sensible default. What you see after a few weeks of production traffic is a matrix tuned to your workload.
Trade-offs
Honest accounting of what 5-channel retrieval costs compared to single-vector RAG:
- More infrastructure. You need Postgres with pgvector, a Postgres full-text index, and Neo4j. Single-channel RAG needs one of those.
- Indexing overhead. The graph channel requires entity extraction at ingest time to build the knowledge graph edges. That's an extra LLM call (or NER pass) per memory.
- Parallel latency. Channels run concurrently, so latency is bounded by the slowest channel, not the sum. But the slowest channel is usually the graph channel, and it's slower than a single cosine similarity search.
- Weight tuning. The defaults work for general traffic. Domain-specific deployments benefit from tuning the weight matrix per query type — which means you need a feedback signal to learn from.
- More failure modes. Each channel can fail independently. The fusion logic has to degrade gracefully when a channel returns nothing (or times out).
None of these are free. They're the price of getting retrieval results that actually answer the query instead of returning something conceptually close.
Conclusion
Single-vector retrieval made sense when RAG was young and the corpus was a pile of static documents. Agent memory is different. It's temporal, personal, emotional, and entity-rich. The retrieval layer has to match that shape.
5-channel retrieval isn't a clever optimization. It's the minimum viable architecture for memory that works across the query types agents actually get. If your RAG system is still running on one channel, the question isn't whether it's losing recall — it's how much, and on which query types.