The term "semantic memory" comes from cognitive science, not computer science. Endel Tulving introduced it in 1972 to describe long-term knowledge that exists independent of personal experience — facts, vocabulary, concepts. The capital of France is semantic memory. Your first day at a new job is episodic memory. In AI agents, the same distinction applies: semantic memory is the layer that stores and retrieves what the agent knows, while episodic memory stores what the agent experienced.
In practice, semantic memory in AI agents means the retrieval layer that finds past interactions by meaning rather than exact keyword match. It's the reason an agent can answer "what did we discuss about authentication?" without the user typing the exact words that appear in a stored memory.
This post explains how that layer actually works — the mechanics of embedding and retrieval, the threshold decisions most engineers get wrong, where semantic retrieval structurally fails, and what a production implementation looks like end to end.
Assumed audience: Engineers building AI agents who want to add long-term memory. Familiarity with vector databases and embeddings helps. If you've used pgvector or Pinecone before, the implementation details will be immediately applicable.
How Semantic Memory Retrieval Works
The core mechanism has three steps.
Step 1: Embed. When a memory is created — a conversation turn, a fact, an event — it's passed through an embedding model that converts the text into a dense vector of floating-point numbers. OpenAI's text-embedding-3-small produces 1536 floats. Each float represents something about the meaning of the text, distributed across all 1536 dimensions. No single dimension means anything interpretable; the meaning is in the relative positions of vectors.
Step 2: Store. The vector is stored in a vector database alongside the original text and any metadata (timestamp, user ID, session ID). pgvector, Pinecone, Weaviate, and Chroma are common choices. The storage concern is just an index that supports fast nearest-neighbor lookup over high-dimensional vectors.
Step 3: Retrieve. When a user queries the agent, the query is embedded using the same model. The resulting query vector is compared against all stored memory vectors using cosine similarity. The top-k most similar results above a minimum threshold are returned.
The pgvector SQL for this looks like:
SELECT id, content, 1 - (embedding <=> $1::vector) AS score FROM memories WHERE namespace = $2 ORDER BY embedding <=> $1::vector LIMIT $3
The <=> operator returns cosine distance — 0 means identical direction, 2 means opposite. Subtracting from 1 converts it to cosine similarity, where 1 means identical. The threshold filters out memories that are too dissimilar to be useful.
Why cosine similarity specifically? Because it measures angle between vectors, not magnitude. "The auth service failed" and "authentication service is down" will have high cosine similarity even though they share almost no tokens, because their embeddings point in a similar direction in the high-dimensional space. This is what "retrieval by meaning" actually means in practice.
The Similarity Threshold Problem
Most tutorials on semantic retrieval pick a threshold — typically 0.7 — and move on. This is the part that causes silent failures in production.
The same threshold means different things for different queries. Consider two examples:
"What did we discuss?" — three words, exploratory intent. The user wants to browse. They don't have a specific memory in mind. A threshold of 0.7 will return almost nothing for this query, because most stored memories aren't that similar to a three-word query about the concept of discussion itself. You'll miss everything that's relevant but not tightly similar.
"What specific error code appeared in the auth token refresh failure last week?" — twelve words, precise intent. The user knows exactly what they're looking for. A threshold of 0.5 will surface a dozen loosely related authentication memories, none of them the specific incident. You'll bury the signal in noise.
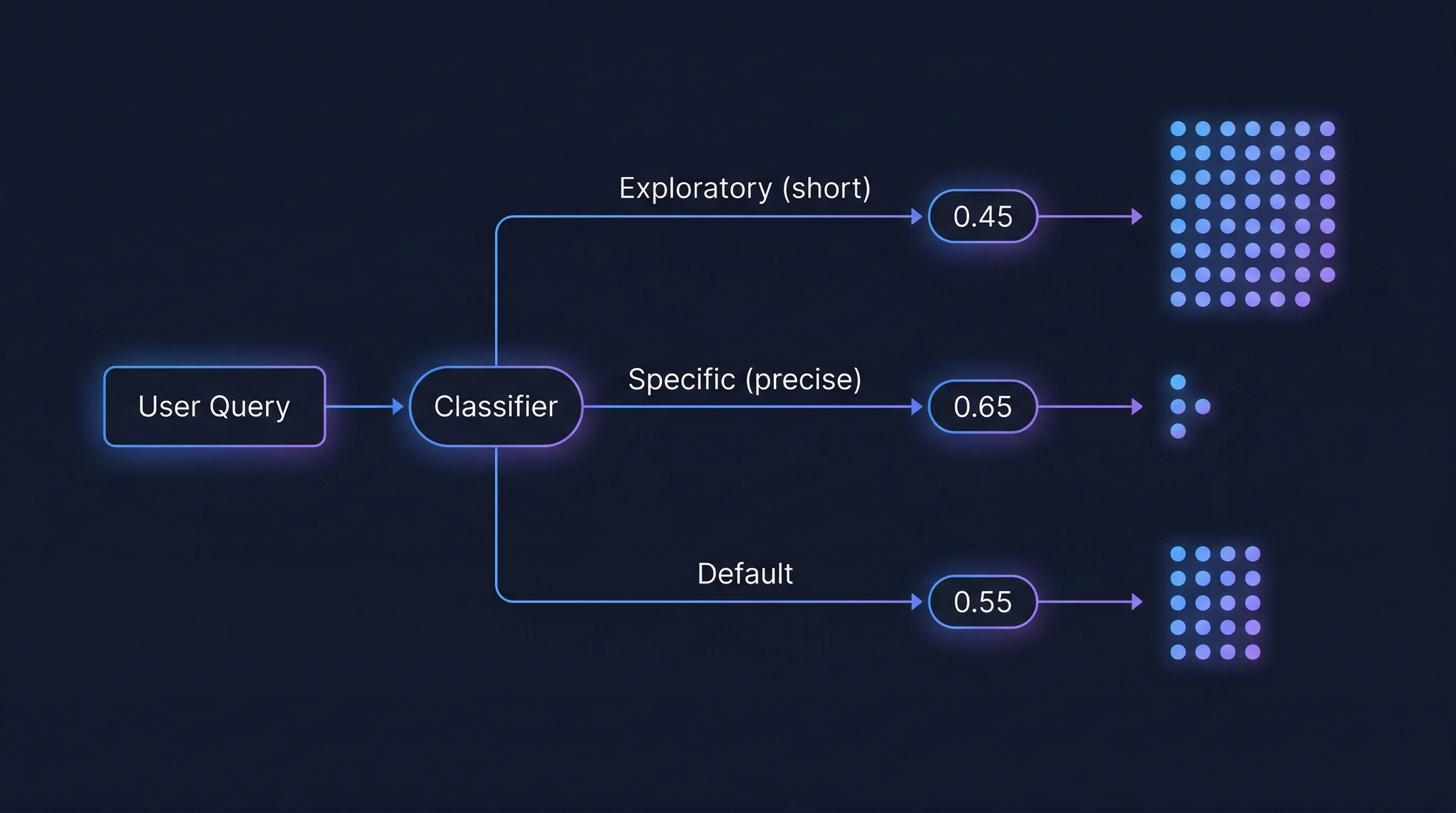
The fix is to classify query type first, then apply the corresponding threshold:
- Exploratory queries (very short, browsing intent): use a lower threshold like
0.45— cast a wide net, surface distant but potentially relevant connections - Specific queries (longer, precise intent): use a higher threshold like
0.65— precision over recall - Cross-session queries (querying memories from other sessions): slightly relaxed, around
0.50 - Default (ambiguous or medium-length queries): fall back to
0.55
Classification doesn't need to be complicated. Query length is a reasonable first-order proxy: very short queries are usually exploratory, longer queries with specific technical terms are usually precise. Temporal keywords ("last Monday", "yesterday") and emotional keywords ("frustrated", "happy") are also useful signals for routing to specialized channels rather than pure semantic retrieval.
A single cosine similarity cutoff applied to all queries isn't a retrieval strategy. It's a single parameter set once and hoped for the best.
Choosing an Embedding Model
The embedding model determines the shape of your vector space — the quality of semantic similarity, the dimensionality of stored vectors, and the latency and cost of every ingest and retrieval operation.
Common choices and their tradeoffs:
- text-embedding-3-small (OpenAI, 1536 dims) — Fast, cheap, good quality. The default for most agent memory systems. About 5x cheaper and faster than the large variant.
- text-embedding-3-large (OpenAI, 3072 dims) — Better semantic precision, especially for long or technical text. Cost and latency multiply accordingly.
- Mistral Embed (256 dims) — Very fast, very small storage. Lower semantic precision. Useful when latency is the top constraint.
- Nomic Embed Text (768 dims) — Open-weight, hostable locally. Good for private deployments where API calls to external providers aren't acceptable.
- Gemini Embedding (3072 dims) — Strong performance on multilingual content.
One practical concern: once you've embedded millions of memories with one model, switching to a better model means re-embedding everything. The similarity space changes when the model changes — a vector from text-embedding-3-small isn't comparable to a vector from text-embedding-3-large. Plan for this before you pick a model. Running two models in parallel during a transition, then gradually migrating, is a common approach.
A schema design that helps with this: store all vectors in a fixed-width column regardless of the original model's dimension, using zero-padding for smaller models. A 256-dim Mistral vector stored in a 1536-dim column gets 1280 zeros appended. Cosine similarity is direction-based, so trailing zeros don't affect the score — two vectors pointing the same direction score the same whether they have 256 or 1536 components. You pay a storage overhead but avoid schema migrations when you switch models.
Beyond Semantic: Multi-Vector Memory
A semantic embedding captures what was discussed. It doesn't capture when, how it felt, or in what context.
For simple document retrieval, that's fine. A static FAQ doesn't have an emotional history. For agent memory — which is personal, temporal, situational — a single semantic vector is missing several dimensions of meaning.
A multi-vector approach stores several embeddings per memory, each capturing a different signal:
- Semantic vector — what was discussed (dense embedding, provider-dependent)
- Temporal features — recency, time of day, day of week, encoded as numeric features alongside the semantic vector or applied as a decay multiplier at retrieval time
- Emotional trajectory — the emotional arc of the interaction, encoded separately from the content (useful for queries like "when I was frustrated about the deploy")
- Context features — task type, domain, complexity — categorical features that describe the situation rather than the content
At retrieval time, the scores from each vector type are combined with weights: semantic typically carries the most weight, but emotional queries can shift the balance toward the emotional vector, and precise factual queries can down-weight everything except semantic and keyword signals.
This is a meaningful complexity increase over single-vector retrieval. The payoff is that "find the memory where I was debugging authentication last Tuesday afternoon" can actually be answered — semantic catches "authentication debugging", temporal catches "last Tuesday afternoon", and the weight combination surfaces memories that score well on both.
Where Semantic Memory Retrieval Fails
Even a well-tuned semantic layer with adaptive thresholds will fail silently on four structural query types. These aren't bugs — they're inherent limitations of what cosine similarity over dense embeddings can represent.
Temporal anchors. "What did I discuss last Monday?" Cosine similarity has no concept of time. The semantic embedding of "last Monday's authentication discussion" and "authentication discussion" are nearly identical — the temporal anchor is invisible in the embedding space. Temporal queries need a separate mechanism: typically a recency decay term applied to the semantic score, or a dedicated temporal index on the timestamp field.
Exact identifiers. "Find the memory where error code E_AUTH_404 appeared." Dense embeddings are designed to generalize — to understand that "E_AUTH_404" is related to "authentication failure". That generalization is exactly wrong here. You don't want the closest semantic neighbor to E_AUTH_404. You want the memory that contains E_AUTH_404 verbatim. Full-text search handles this; dense retrieval doesn't.
Multi-hop reasoning. "Who was the person my manager mentioned in the architecture review?" The answer requires traversing a chain: manager → their mentioned-person in the context of architecture. Dense retrieval returns memories semantically similar to the full query string. The answer is rarely semantically similar to the question — it's connected to it through a graph of relationships. A knowledge graph with typed edges handles this; a vector index doesn't.
Inferred emotional state. "When was I confused about the API design?" The word "confused" may never appear in any stored memory. The confusion was observable from behavioral signals — repeated questions, longer session durations, more revisions — not from language. A semantic embedding of "confused about API design" can't retrieve memories where confusion was inferred rather than expressed.
Recognizing these failure modes is important not just for building better systems, but for setting correct expectations. If your agent's memory only has a semantic channel, users will notice these four classes of queries silently returning the wrong result or no result. The fix in each case is a different retrieval signal — temporal, keyword, graph, or emotional — not a better embedding model.
How MetaMemory Implements Semantic Retrieval
MetaMemory's semantic channel implements the concepts above with a few specific design decisions worth examining as a concrete example.
Adaptive thresholds. Query type is classified on every retrieval call. Exploratory queries (3 words or fewer) use a 0.45 threshold. Specific queries use 0.65. The default is 0.55. Cross-session retrieval uses 0.50. These thresholds are configurable per deployment for domain-specific calibration.
Multi-vector scoring. Each memory stores four vectors: semantic (1536+ dims via the configured provider), emotional trajectory (128 dims), process sequence (128 dims), and context (64 dims). The semantic vector carries the highest weight in the combined score, with emotional trajectory as the second signal. Process sequence and context play supporting roles. For emotional queries the weight balance shifts — emotional trajectory increases at the expense of semantic. The same infrastructure, different weight profile per query type.
Single-embedding optimization. When multiple retrieval channels run in parallel, the query embedding is computed once and passed to every channel that needs it. The temporal channel, for instance, applies an exponential recency decay to semantic scores — it needs the same query embedding as the semantic channel but produces a different ranked list. One API call amortized across all channels.
Dual use of cosine similarity. Retrieval uses cosine similarity as a floor — memories below the threshold are excluded. Consolidation uses it as a trigger — memories above 0.85 similarity are merged. When two memories score ≥ 0.85, they're saying nearly the same thing, and keeping both wastes storage and degrades retrieval quality by inflating apparent relevance. An LLM summarizes the cluster and replaces the duplicates with a single consolidated memory.
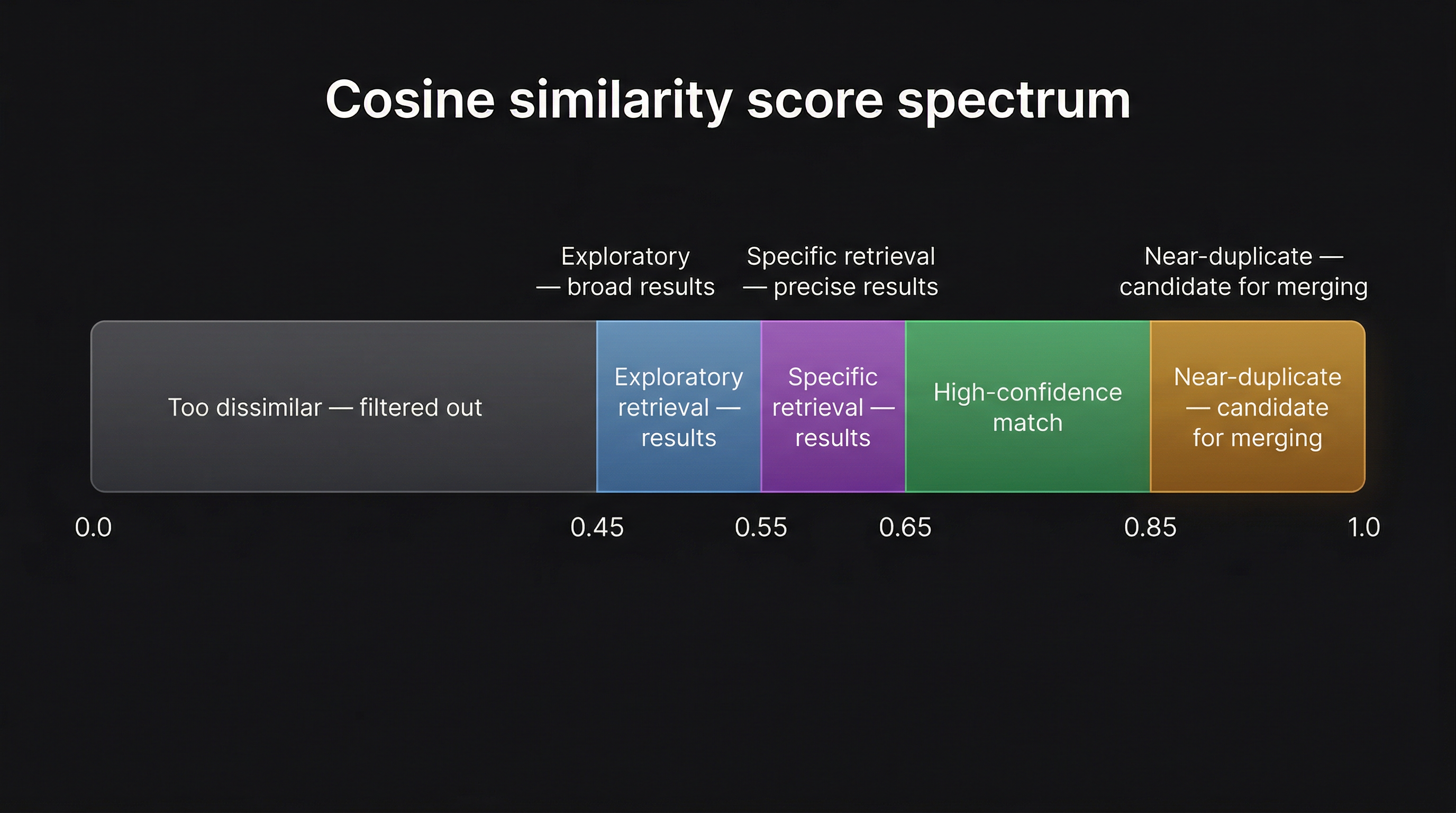
The spectrum above shows the full range of what cosine similarity communicates in a memory system. Most implementations only use one threshold. The full design space spans from retrieval floor to deduplication trigger.
Trade-offs
Building semantic memory for an agent involves real costs that are worth acknowledging:
- Embedding latency on every operation. Both ingest (storing a memory) and retrieval (finding memories) require an embedding API call. External models add 50–200ms per call. This compounds on high-throughput systems.
- Model lock-in. Switching embedding models means re-embedding all stored memories. There's no way around this — similarity scores from different models aren't comparable. Plan your model selection with future migrations in mind.
- Threshold tuning is deployment-specific. The 0.55/0.65 thresholds appropriate for general conversational memory may not work for a legal document system where similarity distributions are different. Every domain deployment needs calibration against real query and memory data.
- Semantic retrieval alone is insufficient for most real agents. The four failure modes above — temporal, exact-match, multi-hop, emotional — cover a substantial fraction of real agent queries. A production memory system needs semantic retrieval as a foundation, and additional channels for the rest.
Conclusion
Semantic memory in AI agents is the retrieval layer that finds past interactions by meaning. The mechanics are well-understood: embed text into dense vectors, store in a vector database, retrieve by cosine similarity above a threshold. The details that determine whether it works in production are less often discussed: adaptive thresholds per query type, embedding model selection with future migrations in mind, multi-vector approaches that capture temporal and contextual signals alongside semantic content, and the structural limits that require additional retrieval channels to overcome.
Getting the semantic layer right is necessary but not sufficient. It's the foundation that every other retrieval mechanism builds on top of.