Episodic memory in AI agents is the long-term memory layer that tracks what happened, when it happened, and how events connect across sessions — as opposed to semantic memory, which stores facts and concepts without a timeline. The distinction comes from cognitive science: Endel Tulving introduced it in 1972 to separate knowledge (semantic) from experience (episodic). In AI agents, it's the difference between an agent that can look up what you discussed and one that understands the arc of your interactions over time.
Most agent memory implementations stop at semantic — short-term or working memory that embeds conversation turns, stores vectors, and retrieves by cosine similarity. That approach answers "what did we discuss?" reasonably well. It fails at "how has this user's understanding of authentication changed over the last month?" — because that question requires temporal ordering, session boundaries, and cross-episode continuity that a vector index doesn't provide.
This post covers the technical mechanics of episodic memory in AI agents: how sessions get encoded, how episode boundaries are detected, how temporal scoring works, and what production episodic memory looks like end to end.
Assumed audience: Engineers building long-term memory for AI agents. Familiarity with vector databases and basic agent architecture helps. If you've read our post on semantic memory retrieval, this post is the direct continuation — it picks up where semantic retrieval runs out.
How Episodic Memory Works in AI Agents
Semantic retrieval stores a vector and retrieves by similarity. Episodic memory stores a richer record — not just what was said, but where it sits in the timeline of interactions.
Every episodic memory requires four fields that pure semantic storage typically omits:
- session_id — which conversation this turn belongs to
- turn_index — where in that conversation it occurred (0-indexed)
- created_at — the real-world timestamp, stored with timezone
- episode_type — whether this is a raw turn, a session summary, or a cross-session consolidated memory
Beyond the standard vector fields, episodic storage needs a time-ordered index on created_at and a sequential index on (session_id, turn_index). Without them, temporal queries and within-session ordering require a full vector scan — which defeats the purpose of having a timeline at all.
The Session Boundary Problem
Before you can build episodic memory, you have to solve a harder problem: where does one episode end and the next begin?
In human memory, episode boundaries are mostly obvious — sleeping between days, leaving a physical location, finishing a task. In AI agents, the signals are weaker. A user might close a browser tab and return an hour later mid-thought. Or have a three-week gap and then ask a directly related follow-up question. Or switch topics completely within a single continuous session.
Three signals are commonly combined to detect episode boundaries:
Temporal gap. If the elapsed time between the last message and the new one exceeds a threshold — typically 20–60 minutes depending on use case — treat it as a new episode. This handles the browser-tab case. The downside: a user who steps away for lunch and returns to the same task gets a new episode even though the context is continuous.
Semantic shift. Compare the embedding of the first turn of the potential new episode against the last several turns of the current episode. If cosine similarity is below a threshold (typically 0.4–0.5), the topic has shifted enough to warrant a new episode. This handles mid-session topic changes but misses topic shifts that share vocabulary with the previous thread.
Explicit signal. The user or calling application explicitly marks a session boundary — via a session-close API call or a conversational signal like "let's start over" or "new question." This is the cleanest signal and the easiest to act on.
A practical approach combines all three with priority ordering: explicit signals always win, temporal gap is the default fallback, semantic shift provides a mid-session override when the topic change is dramatic enough to warrant it.
The decision matters because episode boundaries determine what gets consolidated. Blurry boundaries mean session summaries contain unrelated content, which degrades the quality of cross-session retrieval.
Temporal Scoring and Recency Decay
Once episodes are stored with timestamps, retrieval needs a way to incorporate time as a signal — not just meaning.
The standard approach is exponential decay: multiply the semantic similarity score by a decay factor that decreases over time. The formula is:
final_score = semantic_score × exp(–λ × days_since_created)
Where λ (lambda) is the decay constant. Higher λ means faster forgetting — recent memories dominate. Lower λ means the system is less recency-biased — a memory from 90 days ago competes more evenly with one from yesterday.
In practice this is applied at query time: the semantic similarity score for each candidate memory is multiplied by its decay factor before ranking. With a decay constant of 0.1, a memory from 10 days ago retains roughly 37% of its original score. A memory from 30 days ago retains about 5%.
The problem with a fixed λ: not all memories should decay at the same rate. A memory where the user explicitly said "remember this for later" shouldn't fade at the same rate as a note about what error appeared in a debugging session three weeks ago. The first is intentionally durable. The second is probably stale.
Importance-weighted decay handles this by making the decay rate a function of the memory's importance score:
final_score = semantic_score × exp(–λ × days_since_created × (1 – importance))
An importance score of 1.0 means no decay at all. An importance score of 0.0 means full decay at rate λ. Importance can be assigned explicitly by the user or inferred from signals: high emotional weight, frequent retrieval in past queries, or an explicit "remember this" marker all push importance toward 1.0.
Cross-Session Continuity
The unique contribution of episodic memory — what makes it more than timestamped semantic storage — is cross-session continuity: the ability to understand how a user's situation evolves across separate conversations.
This requires a second storage tier beyond raw turns: session summaries. At the end of each session, the full sequence of turns is consolidated into a single higher-level episodic memory that captures the arc of what happened.
The consolidation process:
- Session ends (via explicit close or inactivity timeout)
- All turns in the session are retrieved, ordered by
turn_index - An LLM summarizes them: main topic, what was resolved, what remains open, dominant emotional tone
- The summary is stored as a new memory with
episode_type = 'session_summary', linked to the samesession_id - The summary is embedded and indexed — making it retrievable by semantic search alongside raw turns
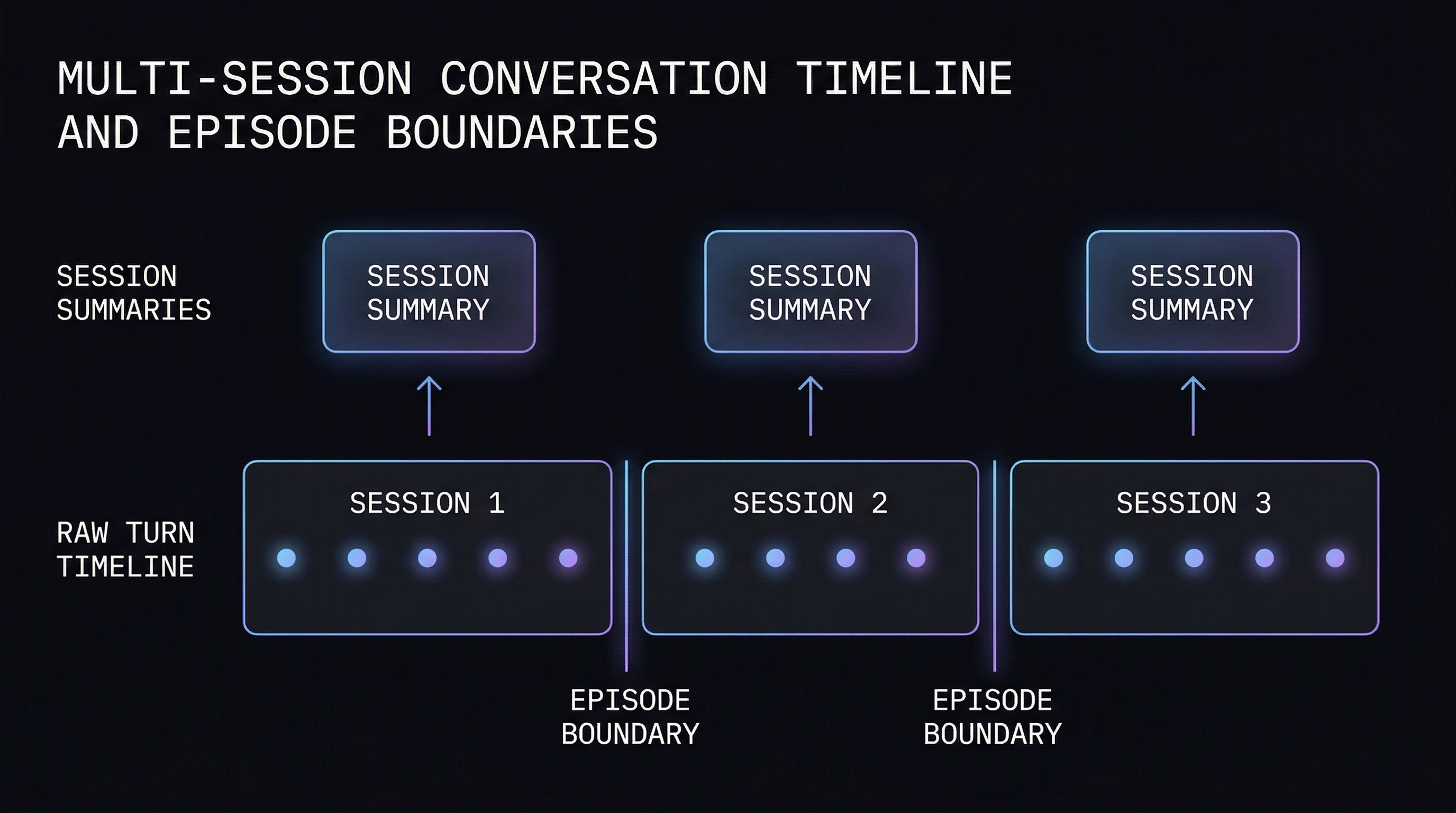
The session summary is what enables queries like "what was I working on last week?" — the answer isn't in any individual turn, it's in the session-level abstraction that consolidation produces. Cross-session continuity goes a step further: at longer intervals, consolidated memories can be merged across sessions. "User has been building an authentication system for three weeks, encountered JWT issues in sessions 3 and 7, resolved in session 8, now working on the refresh token flow" is information that exists only at the cross-session level.
Where Episodic Memory in AI Agents Fails
Episodic memory solves problems that pure semantic storage can't. It also introduces failure modes that pure semantic storage doesn't have.
Summary quality brittleness. Cross-session continuity depends entirely on the quality of session summaries. A summary that misses the main point, over-focuses on one turn, or uses vague language pollutes the episodic store with unreliable high-level memories. Every downstream query that retrieves that summary inherits the error. The semantic layer fails gracefully — a slightly off embedding returns a slightly worse result. A bad session summary returns a confidently wrong answer about what the user was working on last month.
What was said versus what was meant. Episodic memory stores the textual content of turns. A user who types "ok fine, let's try that" after a long argument has expressed something different from a user who types the same phrase after a quick agreement. The text is identical. The episodic meaning is different. Capturing this requires inferring emotional context from behavioral signals — session duration, revision frequency, message length patterns — not just from the words.
Turn-level versus episode-level retrieval mismatch. Session summaries are excellent for "what was I working on" queries but poor for "what was the exact error message I saw in session 7." The specific detail lives in a raw turn, not in the session summary. A production episodic memory system needs to retrieve at both levels and determine which is appropriate for the query. Routing every query through session summaries loses the granularity that raw turns preserve.
Temporal reasoning across episodes. Queries like "how has this user's approach to error handling changed over the last month?" require comparing episodic memories at different timestamps and reasoning about the delta between them. Pure retrieval — finding the most relevant memories — doesn't answer this. It requires ordering memories chronologically and analyzing what changed. This is a reasoning task on top of retrieval, and it's not what a vector index is built for.
How MetaMemory Implements Episodic Memory
MetaMemory's episodic memory layer combines the temporal retrieval channel, the session consolidation pipeline, and importance-weighted decay into a single coherent system.
Session tracking. Every memory is stored with a session_id and created_at timestamp. Session boundaries are detected via a 30-minute inactivity window by default, overridable per deployment. Explicit session-close calls via the API take priority over the inactivity timeout.
Post-session consolidation. When a session ends, MetaMemory consolidates the turns into a session summary using the configured LLM. The consolidation prompt combines overlapping information, preserves unique insights and chronological context, and captures emotional states. The summary is stored as a separate memory tied to the session and added to the vector index. Raw turns remain available for granular retrieval — the summary doesn't replace them.
Temporal retrieval channel. One of MetaMemory's five retrieval channels is dedicated to temporal scoring. When a query arrives, the temporal channel applies importance-weighted exponential decay to semantic similarity scores — recent memories and high-importance memories score higher. The temporal channel's results are merged with the other four channels via Reciprocal Rank Fusion, which normalizes scores across channels and combines them into a final ranked list.
Importance scoring. Importance is assigned at ingest time using three signals: emotional weight (high absolute emotional valence increases importance), explicit importance levels set via the API, and retrieval frequency (memories accessed often accumulate a stability boost over time through an FSRS-inspired spaced repetition model). High-importance memories decay more slowly, remaining relevant across longer time horizons without manual management.
Trade-offs
Episodic memory adds meaningful complexity over pure semantic storage. The costs are real:
- Session consolidation latency. Post-session consolidation requires an LLM call at session end. For high-volume deployments, this is a throughput concern. Asynchronous consolidation — run it in the background after the session ends — is the standard mitigation, but it means the session summary won't exist yet if the user returns immediately after closing a session.
- Storage overhead. Storing raw turns, session summaries, and cross-session consolidated memories means multiple copies of related content at different abstraction levels. Retrieval quality increases; storage costs do too.
- Session boundary errors compound. A misdetected boundary splits one logical episode into two, or merges two unrelated conversations into a single summary. These errors propagate into session summaries and affect all downstream retrieval that depends on those summaries. Boundary quality matters more than it appears at first.
- Summary quality depends on LLM quality. The session summary is only as accurate as the model producing it. Smaller, faster models produce worse summaries. There's a latency-quality tradeoff in choosing the consolidation model that doesn't exist in the semantic-only approach.
Conclusion
Episodic memory in AI agents is the layer that encodes not just what was said, but when, in what sequence, and how it connects to what came before. The mechanics require session boundary detection, timestamp-indexed storage, temporal decay scoring, and post-session consolidation into abstractions that make cross-session queries answerable.
The gap between semantic-only and episodic memory is the gap between an agent that can find relevant content and one that understands your history with it. "What were we working on last month?" requires a different architecture than "what did we discuss about authentication?" Both questions are real. Only one of them semantic retrieval alone can answer.